TL;DR
- Algorithmic improvements should be prioritised over brute-force scaling of computational resources.
- Blockchains could enable monetisation of open-source models by providing a coordination layer for incentive mechanisms.
- Tech giants scale compute vertically, community scale compute horizontally through decentralised training.
- Synthetic data scales real-world data, not a replacement.
- Cryptographic primitives could unlock 95% of deep web data, solving the data scarcity problem.
- DePIN enables scale and cost efficiency on collection of real-world data streams for robotics AI.
🦿🦿🦿🦿🦿🦿
There are three main ingredients to continue the Scaling Law and develop a better AI. Some of them are hitting the wall. Crypto is the only way to make the breakthroughs.
Scaling The Model
"1 clever math trick > 10x more FLOPS"
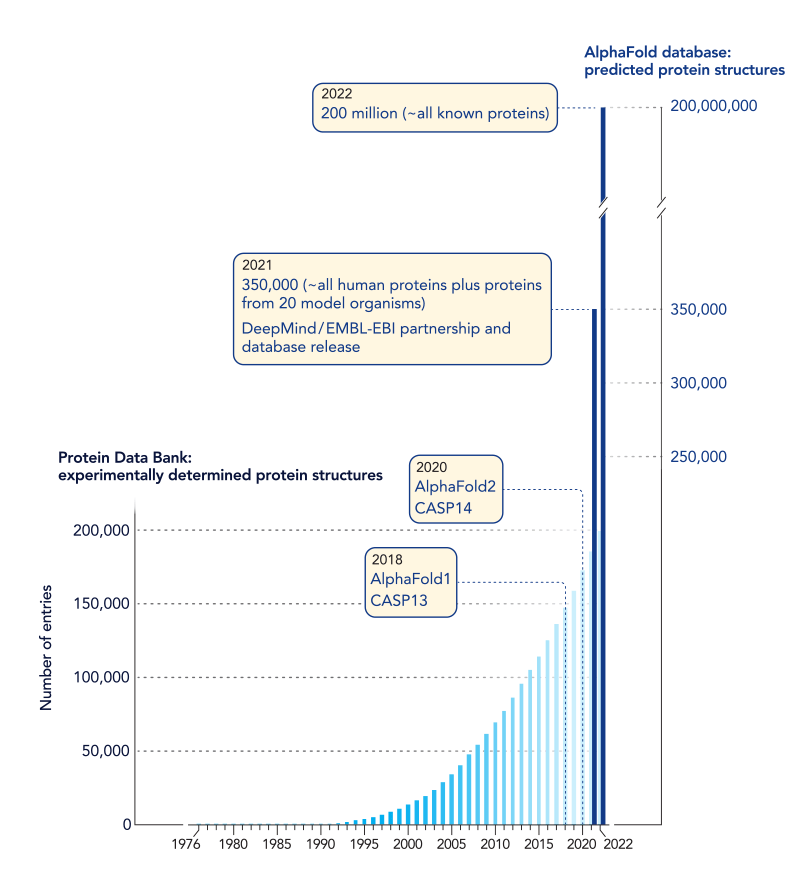
One of the greatest example of how impactful AI software optimization is the AlphaFold 2, Deepmind's model for predicting protein structures. The main update from the prequel is replacement of traditional Convolutional Neural Network (CNN) into a newer Transformer-based architecture, as found in ChatGPT and other LLMs.
As a result, AlphaFold 2 predicted more than 200 million protein structures from over 1 million species, that's almost every known protein on earth. John Jumper and Demis Hassabis who led AlphaFold received chemistry Nobel Prize in 2024.
This 1000x breakthrough was made possible mainly through algorithmic improvements. Alphafold 2 was trained only on 100-200 of GPUs. The dataset available at the protein data bank was only 170,000 protein structures.
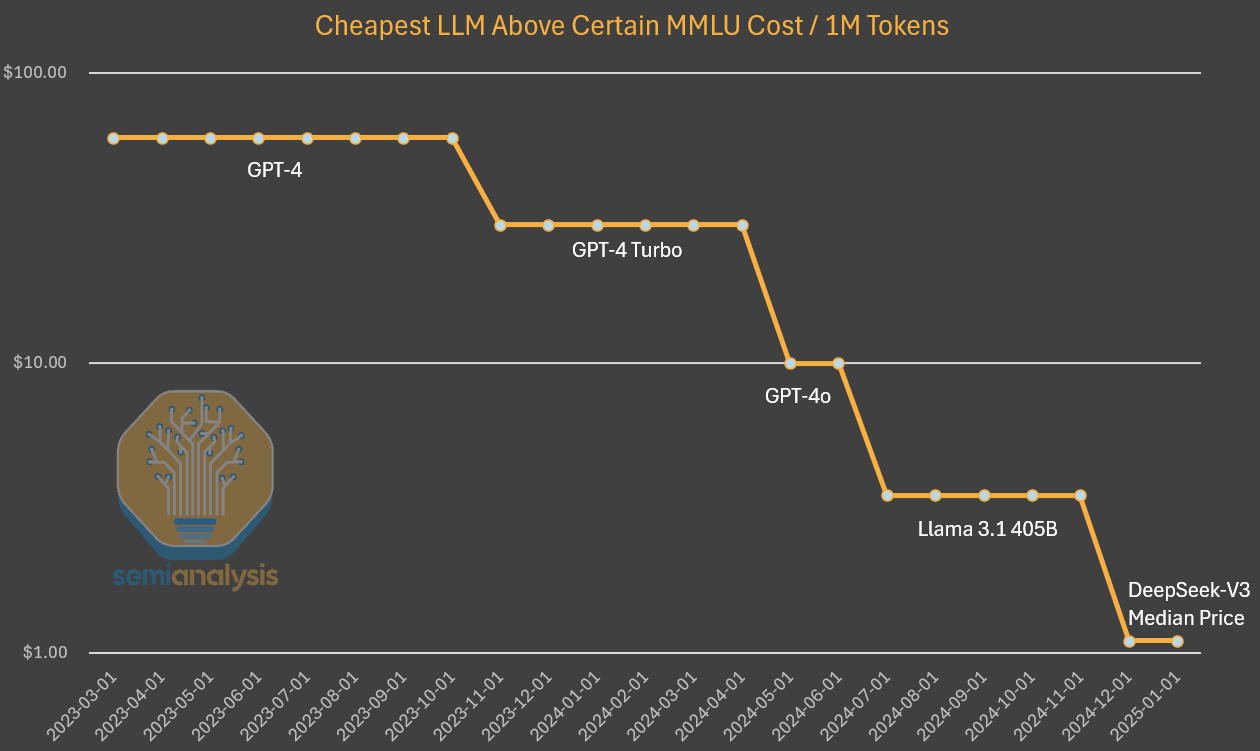
Another breakthrough comes from China. DeepSeek models use Multi-Head Latent Attention (MLA) and Mixture-of-Experts (MoE) architecture, reducing memory usage by 87% and improving throughput by 2-4x. Consequently, Deepseek V3 reduced cost by 5x.
Algorithm innovation has limitless possibilities. Transformer-based architecture should be the beginning, we could have more breakthroughs in the near future. Other than model scaling, another key challenge lies in the governance and sustainability—particularly in the realm of open-source models.
Sustainable Open Source Models
"I'm not scared of AI. I'm scared of what a very small number of people who control AI do to the rest of us, 'for our own good.'"
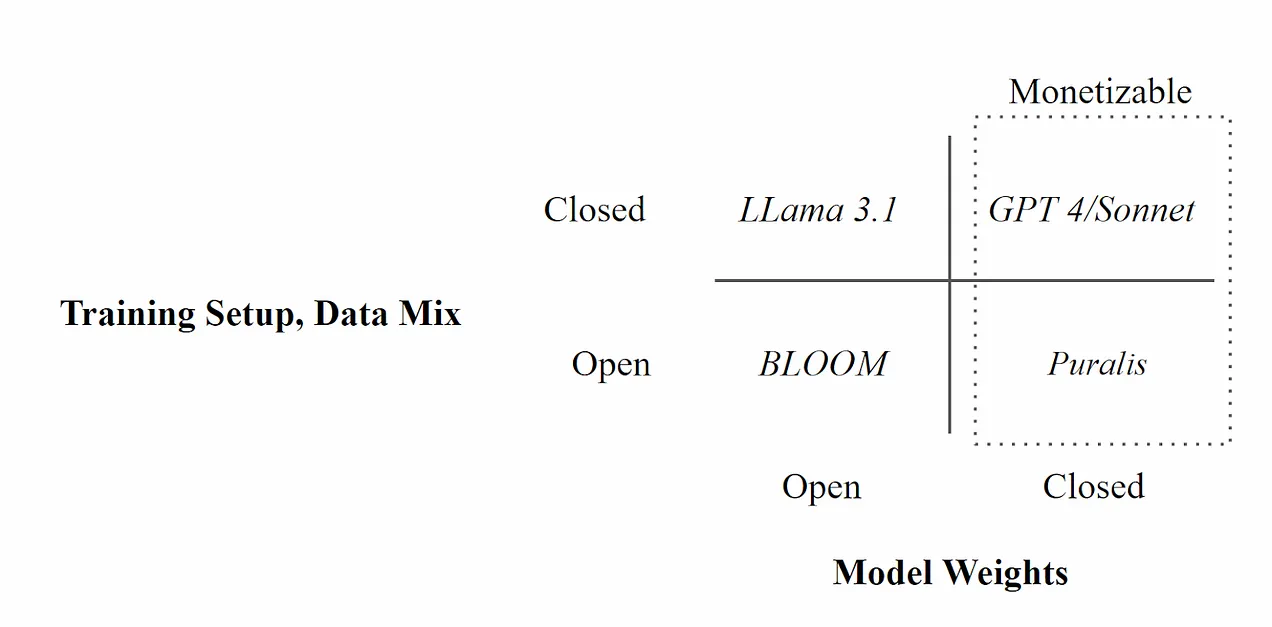
I believe most if not all models should be open source, at least the SOTAs and the future AGIs. The problem with open source is the sustainability of it. So far all open source models are free for all and purely run by altruism. A few teams are trying to solve this problem.
Ritual team wrote a proof of concept about watermarking while Sentient has a scheme called fingerprinting for every models in OML format. Both has the same purpose—to track usage of the open source model and reward developers.
At the time of writing only Sentient had released Dobby, their fingerprinted open source based on Llama 3. Ritual seems to work on watermark behind the scene.
Bear in mind, just like any open source softwares, this doesn't stop anyone to 'steal' the model and self-host their own model. For the most part they provide an incentive coordination layer for on open source AI. That's why the restaking service Eigenlayer is supporting Sentient and Ritual.
Furthermore, Pluralis Research is exploring the idea of Protocol Models (PMs) where the models are fractionalized. The weights are kept private but the training setup is open, allowing further post-training while preventing anyone to take control over the whole model.
Whether proprietary or open source, both of them constrained by computational power. As AI models grow in complexity, scaling the compute becomes increasingly challenging, pushing the limits of current hardware.
Flipping The FLOPS
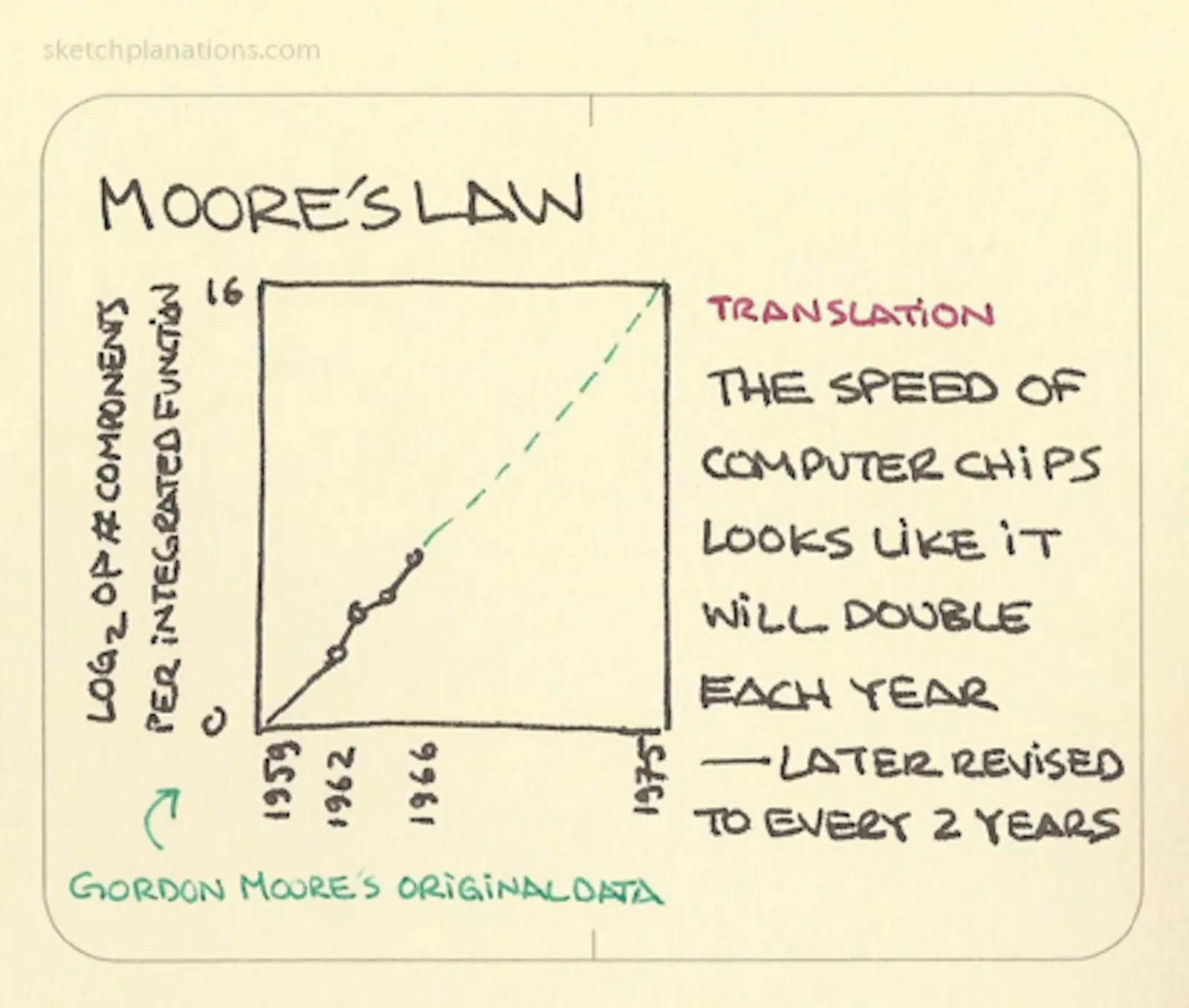
Moore's law is slowing down, as it has been since 1980s.
Chips were getting faster 40-50% every year or double every 2 years. In the recent years, chips are getting faster only 20-30% every year. That's double every 3 years. Pretty good, but not that good in the context of AI.
Recent leg ups in performance on Apple M-series and NVIDIA Hopper are gained from software optimisations, not from transistors count. In the future there could have breakthrough on analog, wetware, or quantum computer. But for now, it is still the era of silicon.
Fortunately, AI compute is parallel. SOTA LLMs today are being trained inside clusters of tens of thousands GPUs across the globe. However this introduce another burden on cost and energy.
GPT-4 had over $73M in training cost and consumed over 50 GWh of energy, equivalent to 40,000 homes in the US for a year. These costs will increase as the model parameters goes to multi-trillions.
Microsoft had a $1.6B deal on Constellation Energy to restore a nuclear power plant to power these GPUs. Google is purchasing small modular reactors (SMRs) from Kairos Energy. OpenAI wants to build a 5-gigawatt data centers, possibly using Oklo micro-reactors or Helion fusion reactors, both backed by Sam Altman.
These gigantic datacenters run on the nuclear power plans seems to lead to a centralisation to Closed AGI, owned and controlled by a few tech giants who can afford this scale. In contrast to centralisation, decentralised AI presents another path toward an Open AGI.
Distributed vs Decentralised
There's an important difference between distributed compute and decentralised compute. Despite both approach does not physically co-located compute power, distributed compute is permissioned and heterogenous, notably the multi-data centers by Microsoft and OpenAI.
On the other hand, decentralised compute is open and homogenous. Anyone who has any type of compute is welcomed to contribute their computing power. The protocol will coordinate the participants of the network.
Prime Intellect and Nous Research are leading the decentralised training method, both released post-trained model codename INTELLECT-1 and Hermes 3, both based on Llama 3 architecture.
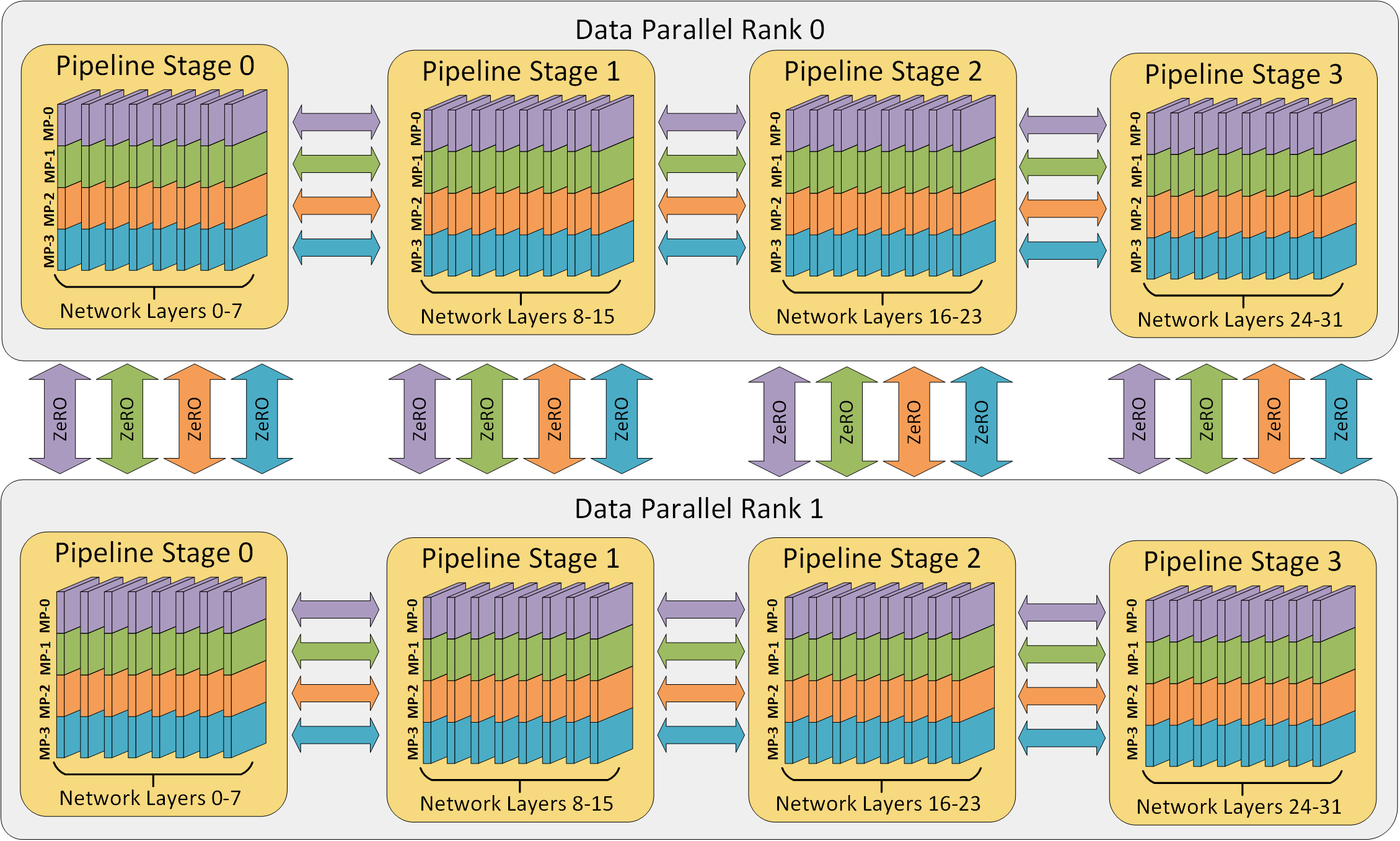
Prime Intellect initially using Open Distributed Low Communication (OpenDiLoCo), based on DiLoCo paper by Google. As the name suggest, it's a form of data parallelism that enables decentralised training under low-bandwith requirement. It works by breaking the datasets into batches while each nodes host the whole model.
Currently they're developing their own training framework prime (prev ZeroBand). Likewise, Nous Research is using data parallelism in their framework DisTRO+DeMo, and their new one Psyche.
Additionally, there's pipeline parallelism papers where the actual model weights are spread among the nodes, such as SWARM from TogetherAI. This method increase bandwith requirement but significantly lower the memory usage, especially as more nodes join the network.
Hyperscalers like Meta is exploring Fully Shared Data Parallelism (FSDP). In the future we shall see something like Alpa by Google, an orthogonal training method where the protocol merge multiple methods of parallelism.
While parallel training remain a research area, it's quite obvious the future of training is not centralised. It increases transparency, verifiability, and efficiency.
Making Data Out of Nothing at All
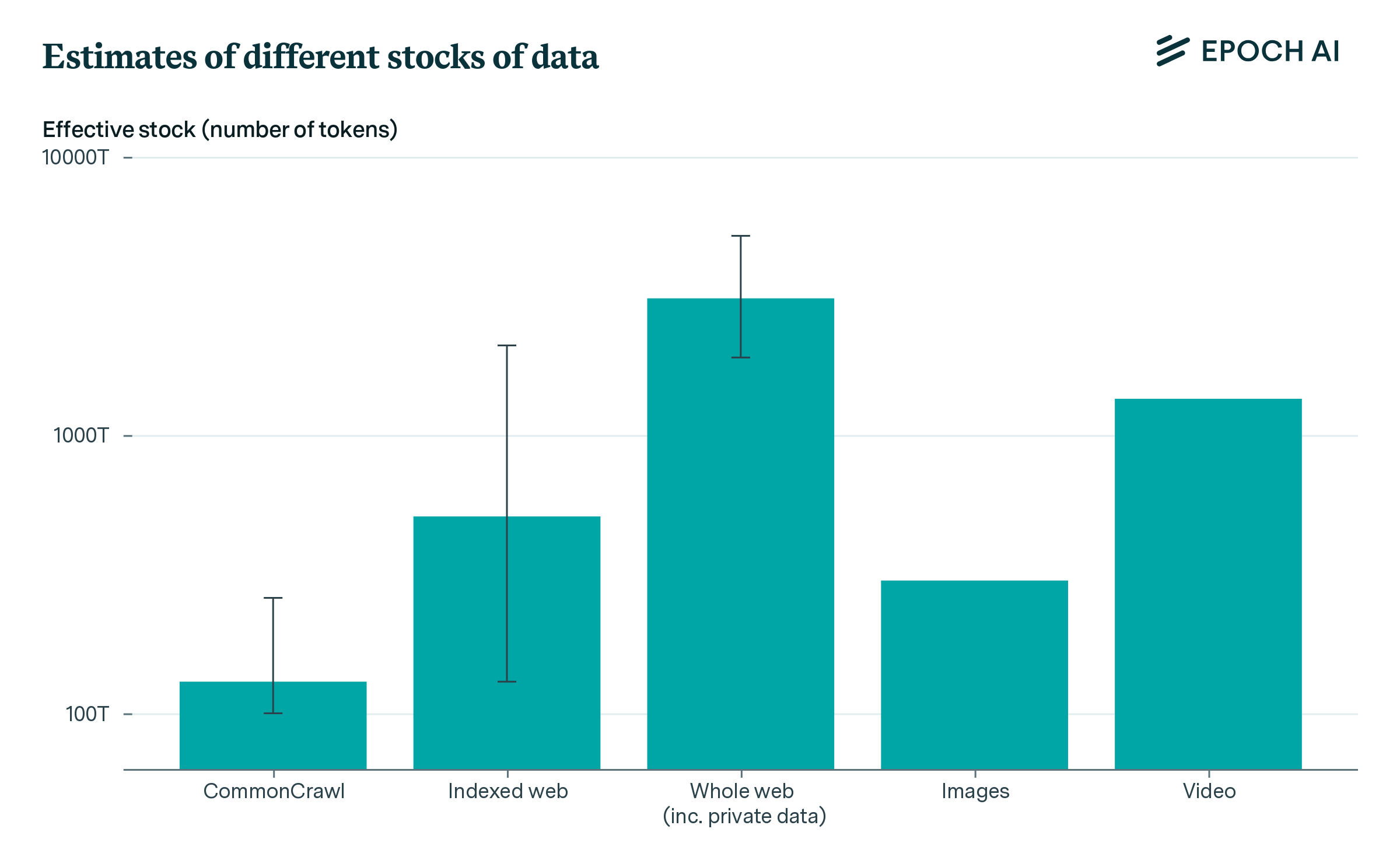
GPT-4 is trained on 13 Trilion tokens. Human-generated data is estimated to be near 10,000 Trillion tokens.
It sounds like we have a lot of reserve, but If frontier LLMs continue to be trained at this rate, we will run out of data by 2028.
If we look at previous models developed by Google Deepmind, synthetic data could be the solution. AlphaGo won over world best player on a board game Go. AlphaGeometry has performance on par with the gold medalist at International Math Olympiad.
Both of them use Monte Carlo Tree Search (MCTS). It's basically just a bunch of random data samples. This method is still used even in the latest AlphaGeometry2.
It seems to be are the answer to data scarcity, but there are two main constraint of synthetics. First off, it's not as nuanced as the real-world data. Second, generating high-quality synthetic data is complicated. Sometimes the data generated is too far from reality, sometimes the data is not diversified enough.
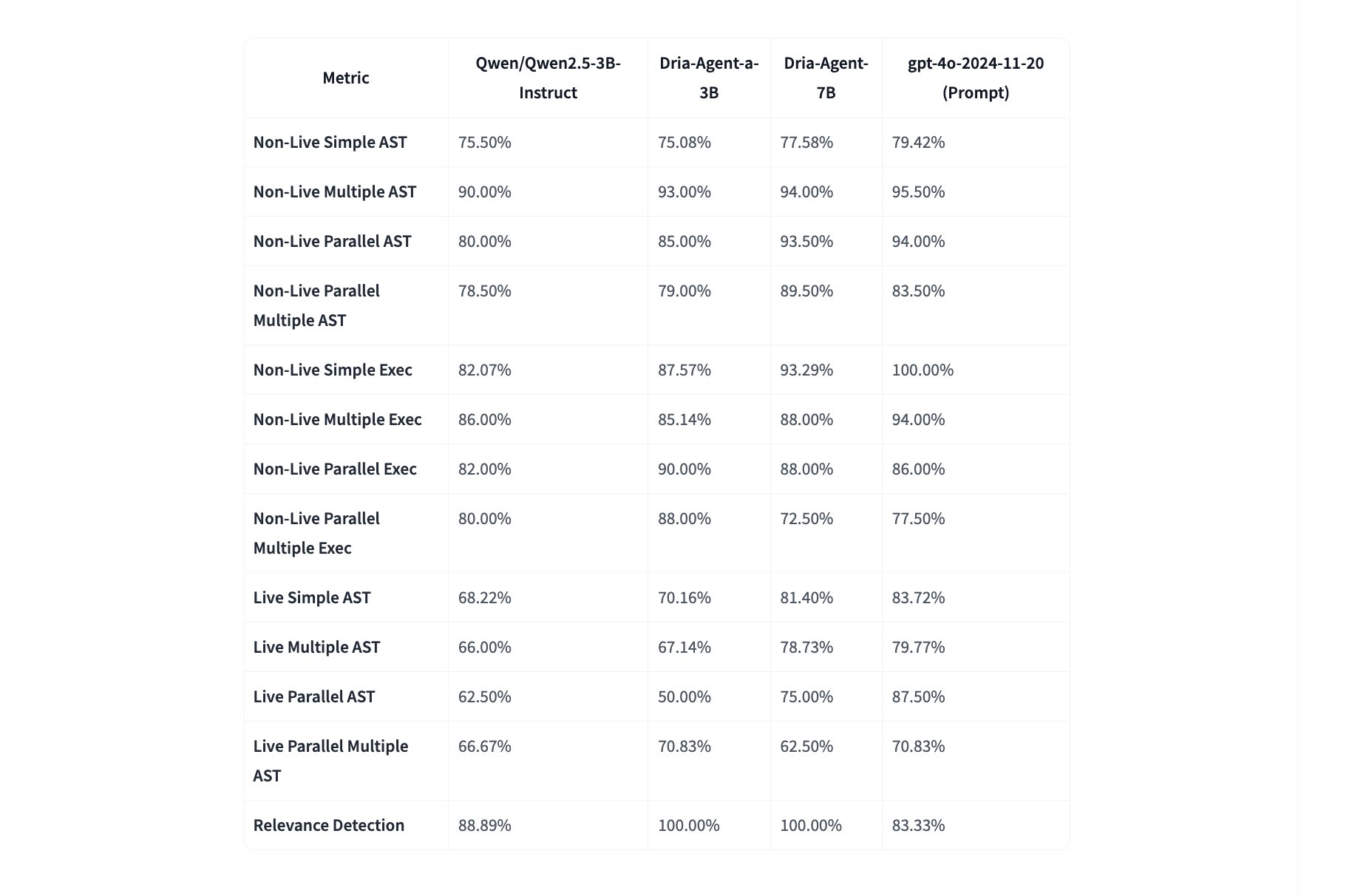
Despite these limitations, synthetic data is here to stay. A small project called Dria had generated synthetic data and scored near GPT-4o in Pythonic benchmark, despite having only 7B parameters.
Prime Intellect interestingly had generated collective synthetic data called SYNTHETIC-1. Previously they also released INTELLECT-MATH, a fine-tuned model on synthetic math datasets.
Looking at the autonomous car space, Tesla and Waymo already trained their models with a mix of synthetic data and real-world data. It seems that real-world data is still needed in this data scarcity problem, except—the data is not really scarce.
Into The Deep Web
Only 5% of data on the web publicly available for all. Most of them is proprietary data resting behind passwords and paywalls.
Imagine if we could train LLMs on private data in the deep web: academic papers, proprietary documents, medical records, private e-mails, or even direct messages. It should be a big step toward AGI. Unfortunately, this strategy is invasive to security and privacy.
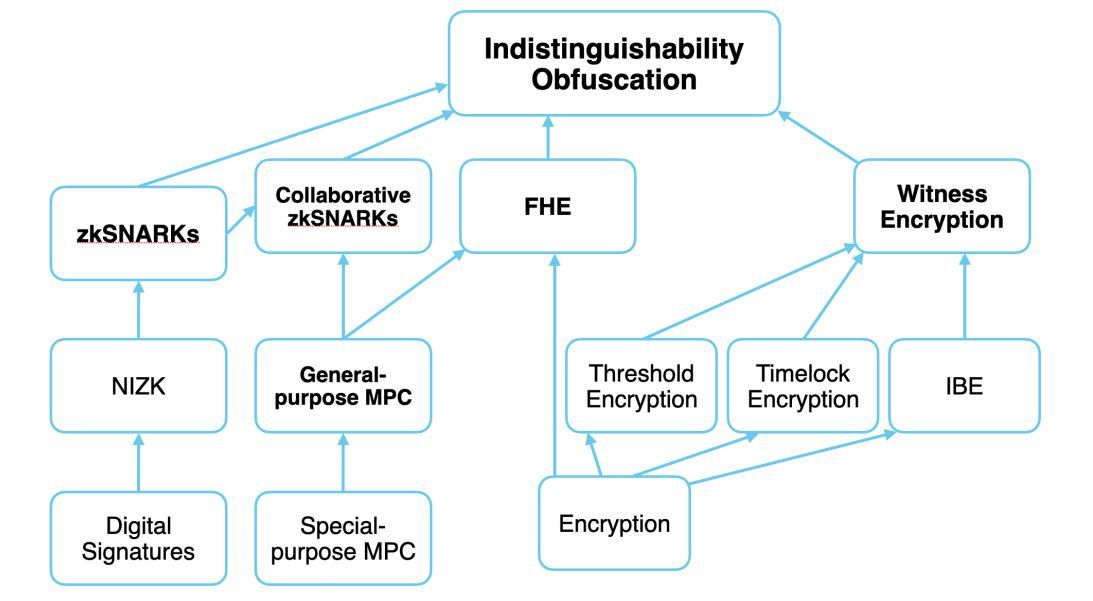
To mitigate these ethical concerns, Privacy-enhancing Technologies (PETs) like ZK, TEE, MPC, and FHE make a path to PPML (Privacy-Preserving Machine Learning), ensuring data confidentiality during AI training.
It's important to note that these primitives are the building bricks toward the endgame of PET—Indistinguishability Obfuscation (IO).
Here's a quick overview on some of these primitives do:
ZK
Contrary to most belief, this primitive only allow private computation if it's done offline, locally, on your device.
In the context of ZKML, it means you'll train a model locally and the math will proof that you've done it on a fixed datasets, cheating is impossible. Your data never leave your device.
Con: ZKML has 1000x overhead compute. (2023)
TEE
TEE or secure enclave is an isolated environment in modern CPU or GPU such as Intel SGX/TDX, Apple SEP, and AMD SEV. This isolation allow private encrypted computation on device.
In the context of ML, you could send an encrypted dataset, decrypt it inside TEE, do the training computation, then encrypt and return the dataset.
Con: TEE is closed source and has vulnerabilities many times.
MPC
Imagine you have a key ABC, you break it into A, B, and C. Alice holds A, Bob holds B, Charlie holds C. No one can have the key except all of those three work together.
In the context of ML, multiple parties will contribute their data an encrypt it with MPC key where it's decryptable only after certain number of parties agree. Only after that the model can train on aggregated datasets.
Con: A small party could collude and break the MPC.
FHE
The holy grail of encryption. FHE allow computation on encrypted data. Decryption is unnecessary. FHEML allows anyone to contribute their encrypted dataset, let the model learn from the encrypted dataset, at the end the model has modified weight without no one has read access to the data, except the owner.
Con: FHEML is 100,000x slower. (2020)
Undoubtedly, there isn't any silver bullet within these PETs to obtain PPML. The good news is that these often debated primitives are not mutually exclusive and can overlap within each other, in certain cases.
Adopting PETs to Train AI
There's more nuance on each of these primitives. ZK is not necessarily zero-knowledge except the computation is private. MPC does make the input private, but not the output. TEE mostly use for inference and only NVIDIA GPU released after H-series support TEE.
TEEML is actually a popular choice for private inference. All thanks to NVIDIA support on TEE since the hopper series, allowing inference at computational overhead below 7%. Last year Phala had partnership with Allora and IOnet to allow training on private data by using TEE. I'm expecting more decentralised GPU networks to enable TEE by default.
ZKML is mostly use for verifiable ML. Giza and Modulus are providing ZKML inference for AI agents. Just last month Bagel published ZKLoRA to verify training. But as I said earlier, ZK does not enable privacy except done locally on client device. I'm closely following EZKL as they're trying to do ZKML locally and protect both the data and the model.
I'd follow Taceo as well. They are developing coSNARK where they use MPC to make ZK proof generation is faster and trustless. I can't find performance of coSNARK being utilised on AI, but in 2023 there's a well-performant MPC-ML training on 63 nodes. SNARK is the most lightweight ZK proof so there shouldn't be that much of overhead.
Luckily ZK is the forefront of cryptography. ZK startups already cumulatively raised billions. Advancement in hardware accelerators like ZK Processing Unit (ZPU) and improvement on the ZKVMs should bring ZK to maturity in less than 5 years.
FHE is great and it is the endgame. Unironically, it's the most inefficient primitive. ConcreteML by Zama takes 100,000x slower on inference. Zama team believe FHE-ASIC could accelerate throughput by 1000x but even then it's still a 100x overhead. I believe FHE needs more than 5 years to mature. Zama's more ambitious than me, planning mass adoption in 4 years. I'm happy to be wrong. As for now, I'm very vigilant on anyone who design a chimera of FHE, which should introduce even more cost, latency, and complexity. There's even a drama on FHE license, but that's out of the scope.
Personally I'm enthusiastic for MPC-based systems thanks to Mikerah's psyops. In the long run, PETs should converge, something like Greco (mix of ZK, FHE, MPC). TEE seems to be the most practical solution for most cases, considering it's already built-in on NVIDIA chips including Hopper and the latest Blackwell series. At the end of the day, it's all about trade-offs.
Scaling The Real-World Data
When it comes to real-world data, there are mainly two obstacles: they're costly and time-consuming. Collecting real-world data can't be accelerated due to physical boundary, while scaling it would cost a lot
For example, NVIDIA Isaac could accelerate robotic AI training in millions of simulations in the omniverse. In the real world, millions of physical robots are needed, that would cost billions of dollars and months of data collection.
This doesn't mean real-world data is irrelevant, synthetic data itself needs a certain 'seed' of real-world data. Real-world data also captures the variability and rare events of the real world accurately.
This is where crypto-economic incentives become relevant, commonly referred to as Decentralised Physical Infrastructure (DePIN). When done right, DePIN could scale to millions of nodes providing concurrent datasets.
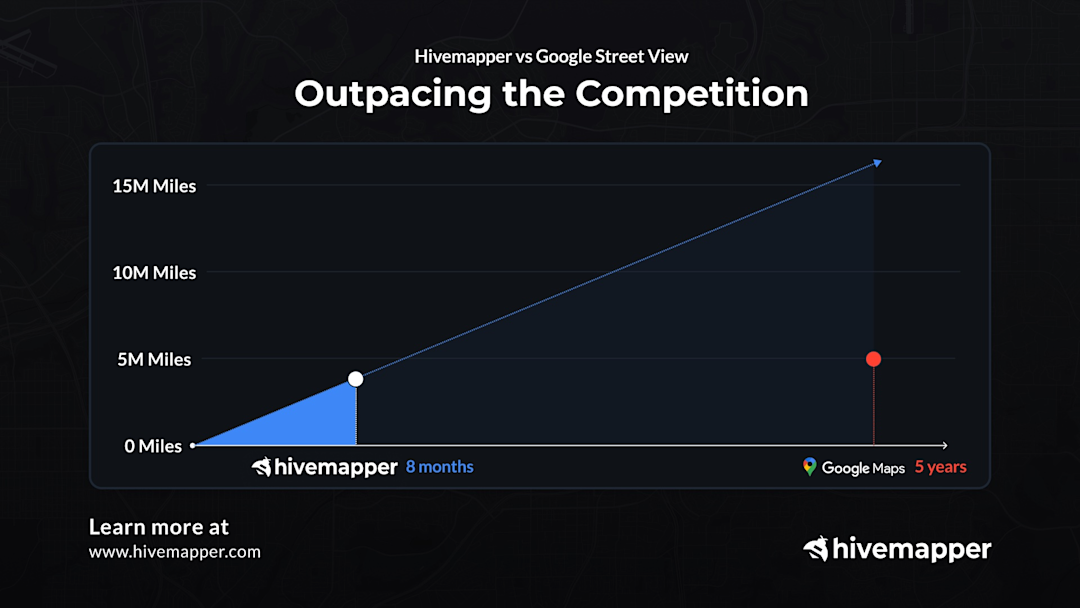
Hivemapper (2015) had mapped over 5 million unique kilometres of the world in only 8 months. For comparison, it took 12 years for Google Street View (2007) to map 10 miles.
This indicates the cost-effectiveness of crowdsourced datasets. Aside from Hivemapper, multiple DePIN projects collect data from decentralised users all over the world.
Perhaps the most notable one is GEODNET with ambitious vision to map the world in 2-10cm accuracy. They're working with Spexi and Wingbits to further build the most detailed map ever. Spexi incentivizes drone owners to create imagery on the map. Wingbits is mapping the sky for aviation coordination.
On the robotics side, Auki and FrodoBots are going to crowdsource data from spatial computing devices. They collect perceptions of XR users and feed those data into AI for robotics. Imagine NVIDIA Isaac but real-world data from thousands of contributors.
All of these possible because of the flywheel of DePIN. The hardwares are much cheaper. Most DePIN devices cost less than $500. Some of DePIN is open for everyone, including even the manufacturer. As seen in GEODNET where the protocol supports devices from 13 companies. The affordability adds up with crypto-incentives attract communities around the globe.
Data recency is another thing that often overlooked for DePIN. Every data collected by the network is recent, meaning it's getting updated occasionally. A view on the Google Map is updated every few months, while Hivemapper map data is always getting an update whenever a contributor is on the road.
These streams of data is something irreplaceable compared to synthetic data generation. As AI evolves, the balance of the two will be play a critical role in shaping upcoming AI systems.
Wrapping Up
The rapid advancement of AI has led to achievements in scalability, efficiency, and model performance. However, this progress is accompanied by significant challenges, including computational limitations, data scarcity, centralisation, and sustainability concerns.
To overcome these bottlenecks, the AI community must balance innovation with responsible governance. Open-source initiatives, decentralised compute solutions, and privacy-preserving technologies offer promising alternatives to traditional AI development models dominated by large corporations.
Moving forward, collaboration across industries and research institutions will be critical in shaping an AI ecosystem that is both powerful and accessible. Whether AI remains an exclusive, centralised technology or becomes a widely distributed tool for collective progress will depend on the choices made today. Ultimately, breaking AI bottlenecks is not just about technical advancements—it is about ensuring that AI remains a force for global benefit.
---

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}