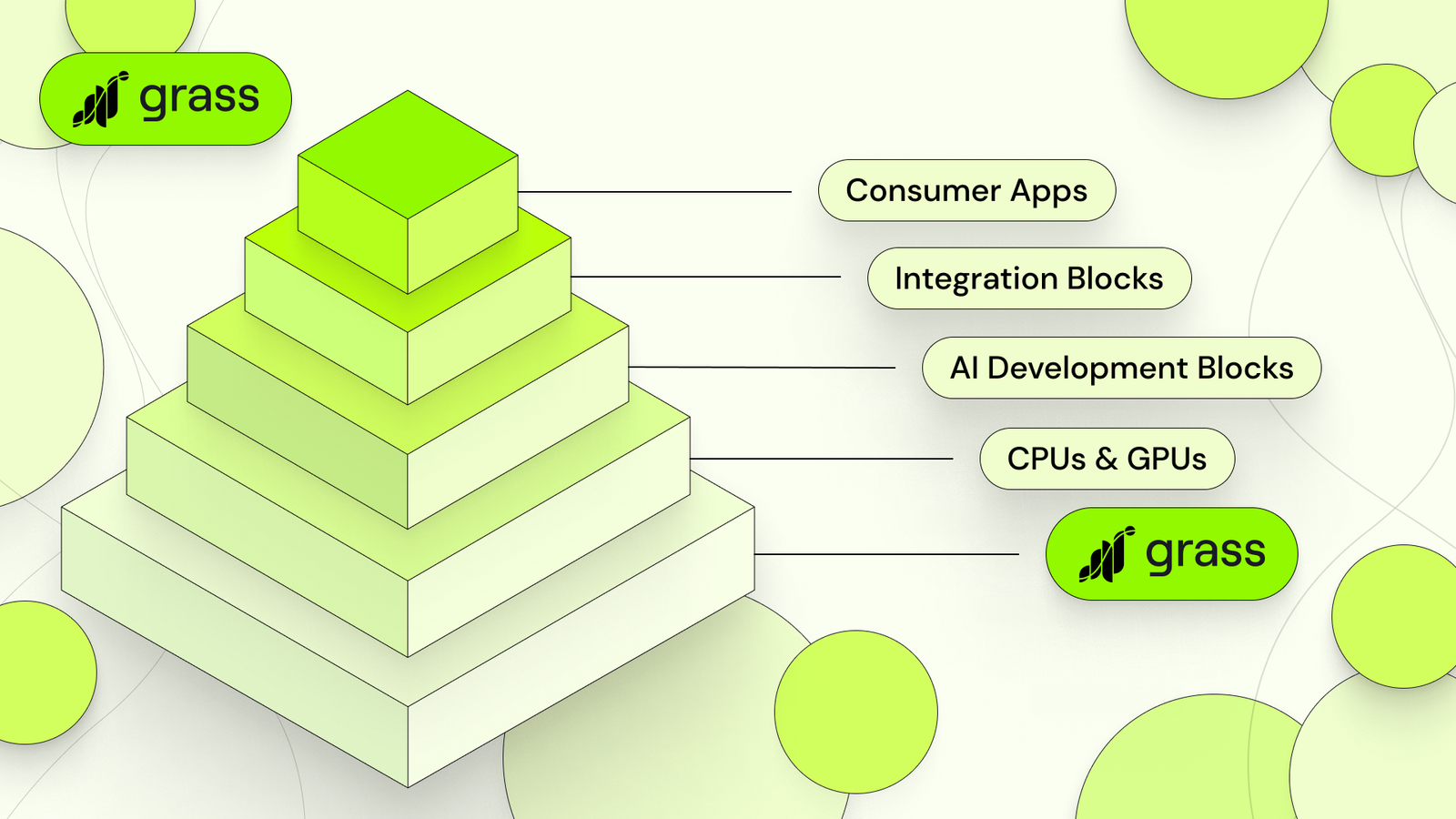
O que é Grass?
Grass é uma rede que usa a banda larga excedente dos usuários para coletar dados públicos da internet. Esses dados são essenciais para treinar modelos de linguagem (LLMs), que são algoritmos de inteligência artificial capazes de entender e responder perguntas em linguagem natural.
Como funcionam os Modelos de Linguagem (LLMs)? Os LLMs analisam grandes volumes de texto da web para identificar padrões entre as palavras. Eles transformam essas relações em "vetores de palavras", que são representações numéricas. Por exemplo, a palavra "espaguete" pode ter uma alta probabilidade de ser associada a "almôndega" porque frequentemente aparecem juntas nos textos.
Por que precisamos de muitos dados? Para que os LLMs possam responder a uma ampla variedade de perguntas com precisão, eles precisam ser treinados com vastos conjuntos de dados. Quanto mais dados processam, mais compreendem as sutilezas e variações da linguagem.
O papel da rede Grass A Grass coleta dados públicos de sites como Wikipedia, Google News e redes sociais como Reddit. Utilizando dispositivos ao redor do mundo, a rede Grass transforma esses dados brutos em conjuntos de dados estruturados, prontos para serem usados no treinamento de IA.
Privacidade garantida Grass coleta apenas dados públicos. Informações pessoais dos usuários não são acessadas nem utilizadas, garantindo total privacidade.
Primeira Camada 2 de Dados Recentemente, a Grass introduziu a primeira camada 2 de dados, uma solução inovadora para melhorar a transparência e a verificação dos dados usados no treinamento de IA.
Por que uma Camada 2? Um dos maiores problemas na IA atualmente é a falta de transparência nos dados de treinamento. Muitas vezes, não sabemos quais dados foram usados para treinar um modelo de IA, o que pode levar a respostas imprecisas ou tendenciosas. A camada 2 da Grass resolve isso registrando metadados que verificam a origem dos dados.
Como a Camada 2 funciona? Quando um nó da rede Grass coleta dados de um site, metadados são gerados para verificar a origem desses dados. Esses metadados incluem informações como a URL do site, o endereço IP do site alvo, um carimbo de data/hora da transação e os dados coletados. Essa informação é armazenada em um "ledger" (livro-razão) de dados, que documenta permanentemente a origem dos dados.
Benefícios da Camada 2
- Transparência dos Dados: Os metadados permitem que os desenvolvedores e usuários saibam exatamente de onde os dados vieram, garantindo que os modelos de IA sejam treinados corretamente.
- Recompensas para os Nós: Os nós que coletam mais dados ou dados mais valiosos podem ser recompensados de maneira proporcional. Isso incentiva a expansão da rede Grass, aumentando a capacidade de coleta de dados.
- Prevenção de Dados Tóxicos: Com a verificação da origem dos dados, é possível evitar o treinamento de IA com dados inadequados ou tendenciosos, melhorando a precisão dos modelos.
A Importância do Ledger de Dados O ledger de dados da Grass é um repositório permanente onde todos os conjuntos de dados coletados são armazenados. Com ele, a Grass pode fornecer dados já estruturados e prontos para uso no treinamento de IA, facilitando o trabalho dos desenvolvedores.
Processador ZK O processador ZK (Zero-Knowledge) ajuda a criar provas dos metadados sem revelar informações sensíveis aos validadores. Isso é essencial para manter a privacidade e lidar com o grande volume de solicitações web que a Grass processa.
Junte-se ao Beta
A versão beta incentivada da Grass está atualmente ativa. Você pode participar do Discord da Grass e seguir a empresa no Twitter para mais informações. Participar da rede permite que você ganhe uma recompensa por compartilhar sua internet não utilizada.

{kind=link}