My first project, as per this post, is Newzy - a helper app for writing new editions of Dot Leap and NFT Review. These are primarily links heavy newsletters, and I know exactly what I need to write them efficiently, and to grow them effectively.
The project is based on Laravel Breeze which makes starting a simple website easy and fast - it comes with some simple database migrations to facilitate user accounts, password resets, and basic profiles, and has an authentication flow built in. It helps that it is based on the remarkably developer friendly Laravel framework, which makes it a breeze to extend.
Back in my web dev days, I used to love doing efficient database design. It is what allowed us to run an enterprise application on a $10 droplet, hitting millions of users per month, thousands of them using hundreds of our database tables at the same time. Scouring the DB and finding that one index reorder or explain query which told me where I could shave off 30% of load time for a massive reduction in compute time and TTI was empowering and encouraging.
These days, things are different. Modern devs use graphql and a host of other unnecessary abstractions that not only introduce dangerous dependencies into the chain, but also often slow things down for the user and increase cost for the creator because it's all designed as a hammer to fit all nails as fast as possible, incurring stunning amounts of tech debt along the way.
I prefer to be focused on the specific problem at hand, so I fired up good old MySQL workbench and got to work.
Model Merging
After some thinking, I came up with what I felt was an acceptable design for an MVP.
However, Breeze comes with its own tables, which I did not design into this model. So our first task is to reverse engineer the default Breeze DB, and then make a merged model of the project DB and the starter kit DB.
MySQL Workbench has a great reverse engineer tool which promptly pulled all the tables in.
There is only one overlapping table with my model here: users. As such, all we have to do to make a merged model, is to copy all except that one into the Newzy model, and modify the newzy users table to match Breeze's table.
Pair Programming with AI
Now that we have a model built, it is time to get modernized. With the help of AI, we can pre-optimize this model AND have it write the migration for Laravel Breeze, such that Breeze can boostrap itself without issue.
First, let's ask good old ChatGPT what it thinks about the exported SQL statement of this model, telling it to ignore Breeze default tables.
It found three bugs - a runaway field Workbench auto inserted while I was fiddling with tables, missing settings for edition_section ID, and links having a too small field. It missed the description field in the roles table for some reason, but that is fine.
Now it is time to convert this SQL into Laravel-compatible migrations.
Migrationification
There are now several tools at our disposal as coders - each of them better than writing a manual migration file.
I use the following AI pair programmers:
- rawdogging ChatGPT as above. Limitation: limited context, forgets what it was doing after a few longer messages.
- Rift by Morph Labs - runs alongside your VS Code and does code completion via ChatGPT API. Remembers context better, and can write code directly.
- Github Copilot X
- Cursor - an AI-first fork of VS Code, with ChatGPT already plugged in. Because it is a fork of VS Code, all the previous approaches work with it too, which means you get a code editor with 3 elite programmers looking over your shoulder at all times 🤩
- Code LLama - Meta's new code-focused AI
- DevGPT - new kid on the block, standalone AI interface for talking to a "coder" about your code.
Let's see who performs best.
This gist is Breeze's original migration. This is what we will feed into the AIs, along with the SQL of the fixed model.
ChatGPT
I used ChatGPT without code interpreter (now known as advanced data analysis). I found it to be not too useful in prior experiments.
ChatGPT generated migrations just fine, but forgot about 4 tables until reminded. It had no additional feedback, even though custom instructions say to be technical, verbose, and provide advice outside the immediate context.
This gist contains ChatGPT's output.
Code Llama
Code Llama, run by Perplexity in this case, has a limited input window size so I had to chunk the prompt. But the responses were much more verbose and complete - going as far as using modern docs, and utilizing indexes, foreign keys, and constraints.
This gist contains the Code Llama output.
The only bug I found was that it missed a class definition in one file: return new class extends Migration in users, so it effectively broke that migration. But this was easy to fix.
DevGPT
This did not do so well, so we will ignore the output. I have a feeling it just makes embeddings from the code and pipes it into ChatGPT.
Rift
Rift was bugged, I will revisit it later, but since it uses ChatGPT, I think it would be the same as that one.
Copilot
Copilot missed the entire ballpark on first prompt. It has no idea what is going on.
Once I gave it more context, and selected the SQL file from which to generate migrations, it started off well...
but then...
Seems to be a common problem.
So, Copilot was unusable.
Cursor
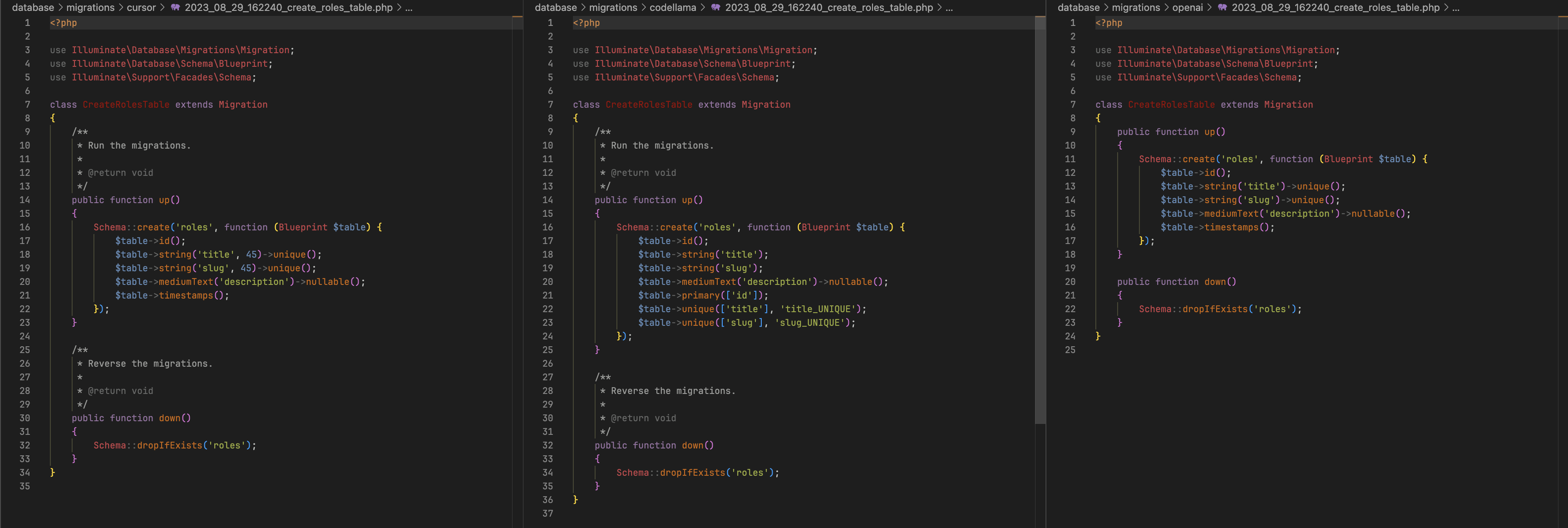
Cursor did it all in-app, which was amazing. It did not generate actual files, but it outputted them nicely in the chat window. This gist has the output. What was really interesting is that Cursor seems to have a cutoff date of knowledge at 01.01.2022., matching ChatGPT's, as indicative by the timestamps it put into the filename proposals.
Code-wise, it performed admirably. Let's compare each output side by side.
Output Comparison
Images might be a little hard to read, so right click and open in new tab to zoom in.
Plans Table
- CodeLlama is a good dev - it uses comments! ➕
- CodeLlama picked increments for ID, whereas the others picked id. CodeLLama followed the SQL model and picked a 4-byte number, whereas the others decided on their own that bigint makes more sense. It is nice that they are thinking outside the box, but this change was not clarified anywhere in any respose and differs from the model, so CodeLlama wins here. ➕
- Only ChatGPT respects varchar length definitions from the model. ➕
- CodeLlama decided that name is nullable, despite both name and slug being defined as NOT NULL. It also set unique on the slug, but then unnecessarily followed up with an index, which is already assumed by unique. ➕ for both CG and CU.
- Description was made TEXT by CodeLLama, and correctly made MEDIUMTEXT by others. ➕ for both CG and CU.
- price related columns were again done per spec by CG and CU, but CodeLlama also decided to give them default values of 0. This actually makes sense because the columns are marked as NOT NULL but have no default, so their values must always be provided on insert no matter what. Everyone gets a ➕ point here.
Users Table
- CodeLlama has failed so hard here it deserves to get a ➖ point. Not only was it not aware it was supposed to write a modification migration, it also outright invented a column
plan_id, and failed to create a class definition. - The
plancolumn was defined by both GC and CU correctly, but only ChatGPT was anal about where to place it - aftercreated_atwhile CU just put it at the end of the column list. This earns 2 ➕ points for CG and one for CU.
Newsletters Table
- CG and CU failed hilariously here by adding columns I did not ask for -
timestamps. This addscreated_atandupdated_atcolumns, despite acreatedcolumn already existing. This is a breaking change from the provided SQL, so they each lose ➖ a point here. - they all set up the foreign key relationship on the
admincolumn correctly - another point for CodeLlama, the only one of the three to actually set up indexes. This setup of indexes also showed me a redundancy - I had a unique key set on
idtwice, once for primary and once for just unique, so I removed the latter from the model and this code. ➕ for CL.
Roles Table
- Same timestamps problem as before, but we already counted points for that in the last table.
- Only CodeLlama cared about the ID primary key, others skipped it. That would be a ➕ point if Laravel did not already auto-set primary key on
id(),increments(),bigIncrements()and other similar functions, so it seems CL is not aware of this. - One minor difference is that CodeLlama likes to set indexes separately, whereas CU and CG chain them (
$table->string('title', 45)->unique();). Inconsequential but interesting. - Only Cursor cared about varchar lengths! ➕
Links Table
- just link in plans, CodeLlama decided to make
urlandtitlenullable, despite clearly being marked as NOT NULL. We already gave it a ➖ point for that though. - interestingly, they all cared about varchar length this time.
- like in plans, CodeLlama decided MEDIUMTEXT should be TEXT on
summary. timestampsinserted again by CG and CU, and primary key only in CodeLlama 🤷♂️- foreign key was set correctly by all, but indexes again only CodeLlama.
Editors Table
- CodeLlama has again decided to make most fields nullable, despite most of them being marked NOT NULL. It also added a field that was never specified - id, so it gets a ➖.
- CodeLlama decided to make some BIGINT fields into INT, which would break the DB foreign key relationships when migrating. ➖
- ChatGPT skipped indexes, so it gets a ➖ because it was the only one failing at this here.
- Foreign keys were done correctly by all.
Editions Table
- again, CodeLlama hallucinates about nullables.
- CodeLlama is the only one respecting the INT size this time, so it regains the point it lost in the previous table for the opposite mistake. ➕
- again, CG and CU add timestamps, and CL is the only one caring about indexes. We already scored this.
Sections Table
- OpenAI was the only one which dropped the ball on varchar length of heading ➖
- CodeLlama hallucinated a different name for the
newslettercolumn, and added_idto it. This would break the migration. ➖ - Strangely, all three added timestamps this time without being asked to do so.
- Indexes again only respected by CodeLlama.
Edition Sections Table
- same as before, CodeLlama inserts
_idat the end of some column names. CodeLlama again only one doing indexes. And all three added timestamps again.
---
Conclusion
It is hard to declare any of the three as absolute winner. Each has its advantages and disadvantages, but I would say that due to accessibility and being "right" most of the time, Cursor wins this race. It also has the added advantage of being aware of your code, and you being able to reference files in chats with it, which makes communication with the agent much easier.
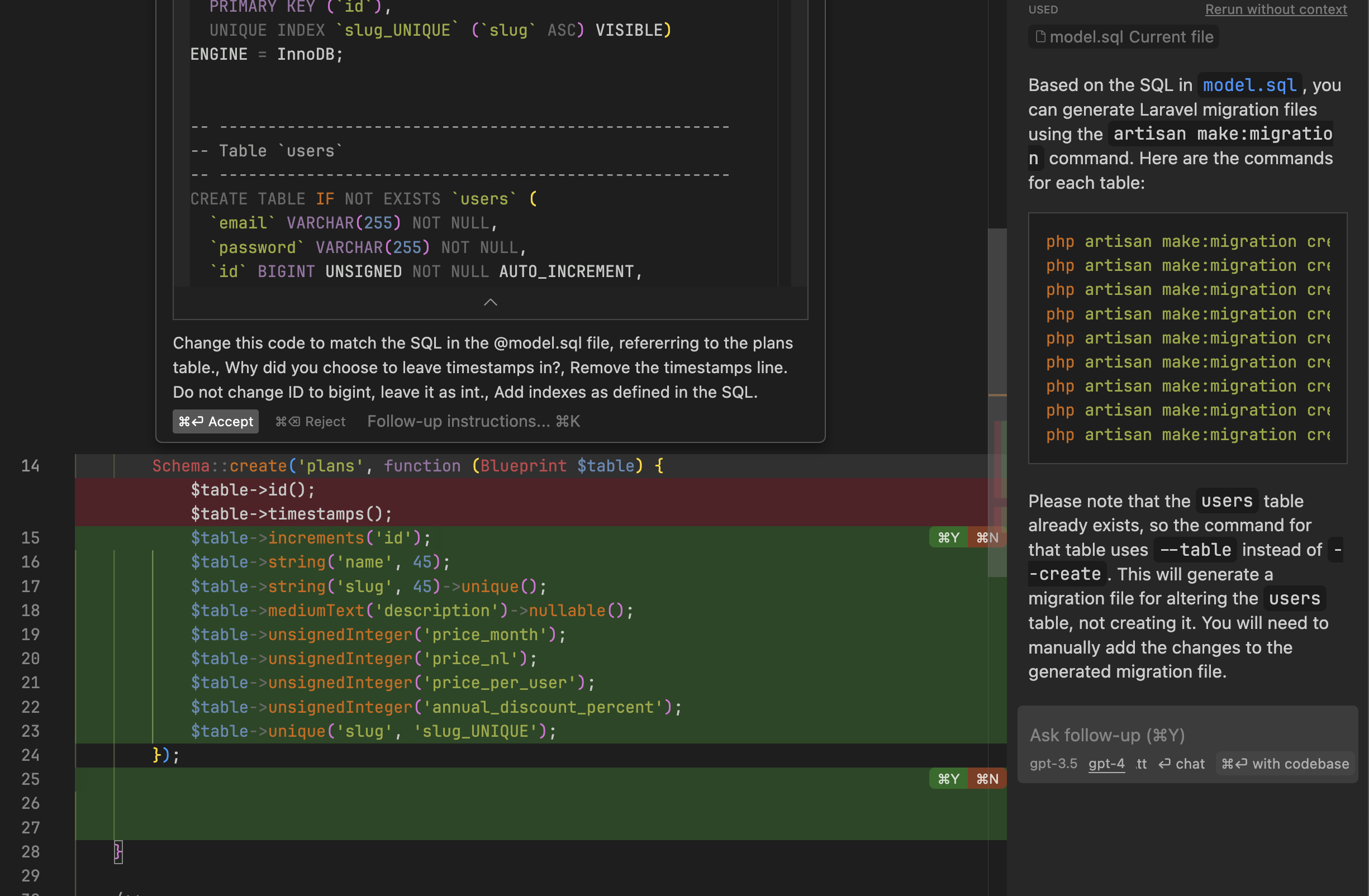
One thing I also noticed in later experiments with Cursor, is if I generate stub migrations with artisan and then select the up function, and then Command+K to request an edit of selected code, with enough instructions it does its job very, very well. Example:
The conversation in the sidebar happened first, and the output in the file itself is by talking to AI directly by selecting a piece of code.
For this reason Cursor will be the main agent I use in helping build Newzy, but I will occasionally double-check with others and report results.
This post was originally published on my decentralized blog.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}